
Some customers are afraid of thin provisioning…
Practically every week I have discussions with customers about leveraging thin provisioning to reduce their storage costs and just as often the customer pushes back worried that some day, some number of applications, for some reason, will suddenly consume all of their allocated space in a short period of time and cause the storage pool to run out of space. If this was to happen, every application using that storage pool will essentially experience an outage and resolving the problem requires allocating more space to the pool, migrating data, and/or deleting data, each of which would take precious time and/or money. In my opinion, this fear is the primary gating factor to customers using thin provisioning. Exacerbating the issue, most large organizations have a complex procurement process that forces them to buy storage many months in advance of needing it, further reducing the usefulness of thin provisioning. The IT organization for one of my customers can only purchase new storage AFTER a business unit requests it and approved by senior management; and they batch those requests before approving a storage purchase. This means that the business unit may have to wait months to get the storage they requested.
This same customer recently purchased a Symmetrix VMAX with FASTVP and will be leveraging sub-LUN tiering with SSD, FC, and SATA disks totaling over 600TB of usable capacity in this single system. As we began design work for the storage array the topic of thin provisioning came up and the same fear of running out of space in the pool was voiced. To prevent this, the customer fully allocates all LUNs in the pool up front which prevents oversubscription. It’s an effective way to guarantee performance and availability but it means that any free space not used by application owners is locked up by the application server and not available to other applications. If you take their entire environment into account with approximately 3PB of usable storage and NO thin provisioning, there is probably close to $1 million in storage not being used and not available for applications. If you weigh the risk of an outage causing the loss of several million dollars per hour of revenue, the customer has decided the risks outweigh the potential savings. I’ve seen this decision made time and again in various IT shops.
Sub-LUN Tiering pushes the costs for growth down
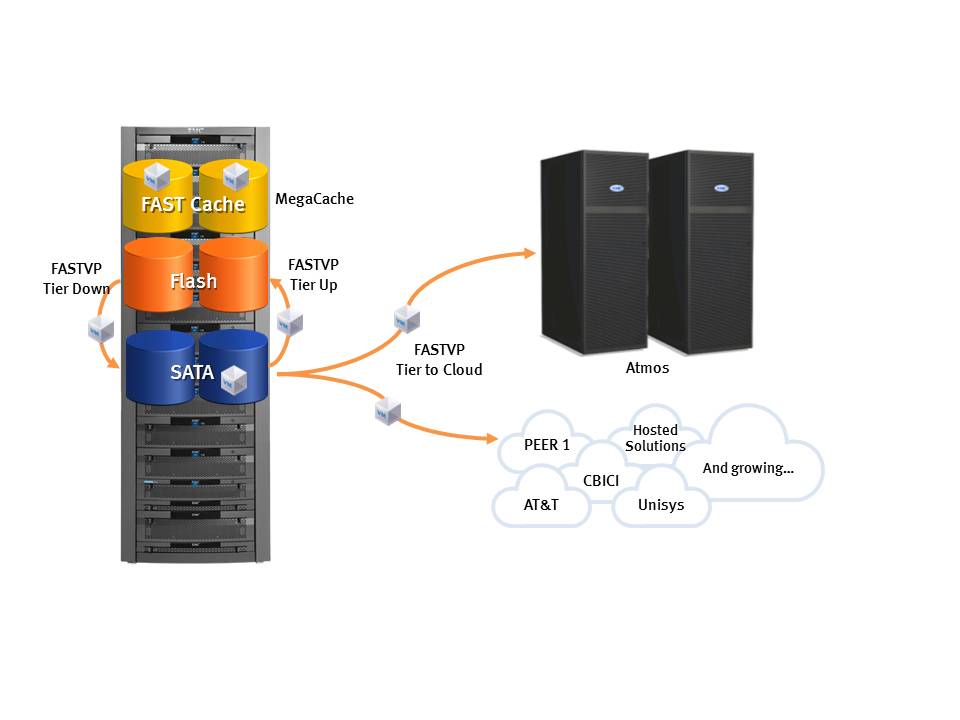
I previously blogged about using cloud storage for block storage in the form of Cirtas BlueJet and how it would not be to much of a stretch to add this functionality to sub-LUN tiering software like EMC’s FASTVP to leverage cloud storage as a block storage tier as shown in this diagram.

Let’s first assume the customer is already using FASTVP for automated sub-LUN tiering on a VMAX. FASTVP is already identifying the hot and cold data and moving it to the appropriate tier, and as a result the lowest tier is likely seeing the least amount of IOPS per GB. In a VMAX, each tier consists of one or more virtual provisioned pools, and as the amount of data stored on the array grows FASTVP will continually adjust, pushing the hot data up to higher tiers and cold data down to the lower tiers The cold data is more likely to be old data as well so in many cases the data sort of ages down the tiers over time and its the old/least used portion of the data that grows. Conceptually, the only tier you may have to expand is the lowest (ie: SATA) when you need more space. This reduces the long term cost of data growth which is great. But you still need to monitor the pools and expand them before they run out of space, or an outage may occur. Most storage arrays have alerts and other methods to let you know that you will soon run out of space.
Risk-Free Thin Provisioning
What if the storage array had the ability automatically expand itself into a cloud storage provider, such as AT&T Synaptic, to prevent itself from running out of space? Technically this is not much different from using the cloud as a tier all it’s own but I’m thinking about temporary use of a cloud provider versus long term. The cloud provider becomes a buffer for times when the procurement process takes too long, or unexpected growth of data in the pool occurs. With an automated tiering solution, this becomes relatively easy to do with fairly low impact on production performance. In fact, I’d argue that you MUST have automated tiering to do this or the array wouldn’t have any method for determining what data it should move to the cloud. Without that level of intelligence, you’d likely be moving hot data to the cloud which could heavily impact performance of the applications.
Once the customer is able to physically add storage to the pool to deal with the added data, the array would auto-adjust by bringing the data back from the cloud freeing up that space. The cloud provider would only charge for the transfer of data in/out and the temporary use of space. Storage reduction technologies like compression and de-duplication could be added to the cloud interface to improve performance for data stored in the cloud and reduce costs. Zero detect and reclaim technologies could also be leveraged to keep LUNs thin over time as well as prevent the movement of zero’d blocks to the cloud.
Using cloud storage as a buffer for thin provisioning in this way could reduce the risk of using thin provisioning, increasing the utilization rate of the storage, and reducing the overall cost to store data.
What do you think? Would you feel better about oversubscribing storage pools if you had a fully automated buffer, even if that buffer cost some amount of money in the event it was used?


{kind=link}