
I came across this press release today from a company that I wasn’t familiar with and immediately wanted more information. Cirtas Systems has announced support for Atmos-based clouds, including AT&T Synaptic Storage. Whenever I see these types of announcements, I read on in hopes of seeing real fiber channel block storage leveraging cloud-based architectures in some way. So far I’ve been a bit disappointed since the closest I’ve seen has been NAS based systems, at best including iSCSI.
Cirtas BlueJet Cloud Storage Controller is pretty interesting in its own right though. It’s essentially an iSCSI storage array with a cache and a small amount of SSD and SAS drives for local storage. Any data beyond the internal 5TB of usable capacity is stored in “the cloud” which can be an onsite Private Cloud (Atmos or Atmos/VE) and/or a Public Cloud hosted by Amazon S3, Iron Mountain, AT&T Synaptic, or any Atmos-based cloud service provider.

Cirtas BlueJet
The neat thing with BlueJet is that it leverages a ton of the functionality that many storage vendors have been developing recently such as data de-duplication, compression, some kind of block level tiering, and space efficient snapshots to improve performance and reduce the costs of cloud storage. It seems that pretty much all of the local storage (SAS, SSD, and RAM) is used as a tiered cache for hot data. This gives users and applications the sense of local SAN performance even while hosting the majority of data offsite.
While I haven’t seen or used a BlueJet device and can’t make any observations about performance or functionality, I believe this sort of block->cloud approach has pretty significant customer value. It reduces physical datacenter costs for power and cooling, and it presents some rather interesting disaster recovery opportunities.
Similar to how Compellent’s signature feature, tiered block storage, has been added to more traditional storage arrays, I think modified implementations of Cirtas’ technology will inevitably come from the larger players, such as EMC, as a feature in standard storage arrays. If you consider that EMC Unified Storage and EMC Symmetrix VMAX both have large caches and block- level tiering today, it’s not too much of a stretch to integrate Atmos directly into those storage systems as another tier. EMC already does this for NAS with the EMC File Management Appliance.
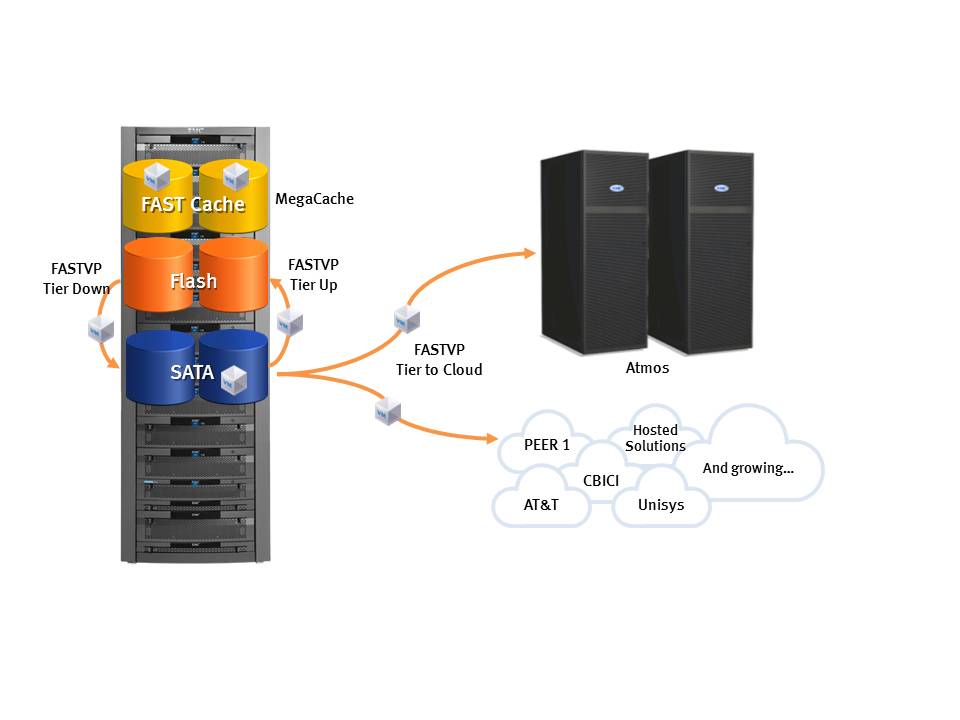{kind=link}

Conceptual Diagram
I can imagine leveraging FASTCache and FASTVP to tier locally for the data that must be onsite for performance and/or compliance reasons and pushing cold/stale blocks off to the cloud. Additionally, adding cloud as a tier to traditional storage arrays allows customers to leverage their existing investment in Storage, FC/FCoE networks, reporting and performance trending tools, extensive replication options available, and the existing support for VMWare APIs like SRM and VAAI.
With this model, replication of data for disaster recovery/avoidance only needs to be done for the onsite data since the cloud data could be accessed from anywhere. At a DR site, a second storage system connects to the same cloud and can access the cold/stale data in the event of a disaster.
Another option would be adding this functionality to virtualization platforms like EMC VPLEX for active/active multi-site access to SAN data, while only needing to store the majority of the company’s data once in the cloud for lower cost. Customers would no longer have to buy double the required capacity to implement a disaster recovery strategy.
I’m eagerly awating the implementation of cloud into traditional block storage and I can see how some vendors will be able to do this easily, while others may not have the architecture to integrate as easily. It will be interesting to see how this plays out.
Josh Goldstein
December 21, 2010 at 8:50 pm
Hi there. Thank you for picking up on our announcement of Atmos support. I’d like to make one tiny, but technically very important correction to your post. You wrote:
“It’s essentially an iSCSI storage array with a cache and a small amount of SSD and SAS drives for local storage. Any data beyond the internal 5TB of usable capacity is stored in “the cloud” which can be an onsite Private Cloud (Atmos or Atmos/VE) and/or a Public Cloud hosted by Amazon S3, Iron Mountain, AT&T Synaptic, or any Atmos-based cloud service provider.”
The correction is that we don’t just store data “beyond the internal 5TB” in the cloud. In fact, we store every bit of information in the cloud, even if it will fit completely within the Bluejet’s on-board storage.
This may seem like a trivial distinction, but it’s actually quite important. By using the cloud (and not our device) as the authoritative data copy, we enable some really cool capabilities with respect to backup and disaster recovery – namely that you get these without having to do anything extra. If the data center where our device resides should experience a site disaster, your data can be easily recovered from anywhere on the Internet using another Bluejet appliance.
If we didn’t do things this way, and only put data into the cloud once it overflowed our on-board storage, you’d still have to use traditional backup and disaster recovery methods to fully protect the data that was on our appliance, but not in the cloud.
The Bluejet Cloud Storage Controller is about much more than simply enabling easy access to the cloud or putting your bits with a service provider instead of in your own data center. It’s about leveraging cloud technology to fundamentally simplify the architecture of storage environments while providing superior data protection to what most organizations can create on their own.
Thanks for affording me the opportunity to clarify this important point.
Regards,
Josh Goldstein
VP Marketing & Product Management
Cirtas
storagesavvy
December 21, 2010 at 9:52 pm
@Josh,
Thanks for the clarification. I actually did pick up on that distinction but I admit I didn’t do a good job making the point in my post. I’m glad you guys produced a product like this and I figure it can only get better from here.
Clearly, storing all data in the cloud and additionally caching hot data gives you the best DR opportunity, especially with cloud services like Atmos (AT&T, etc) which can access the same dataset anywhere, anytime.
Even before the press release I was getting ready to write a similar post practically begging someone to do something along these lines. The one thing missing here is FC attach though. I have many customers who simply won’t deploy iSCSI in their environment, it’s the FC-way or the highway.
Auto-Tiering, Cloud Storage, and Risk-Free Thin Pools «
February 24, 2011 at 3:56 pm
[…] previously blogged about using cloud storage for block storage in the form of Cirtas BlueJet and how it would not be […]